GIS Software Algorithms: Same Analysis and Different Results
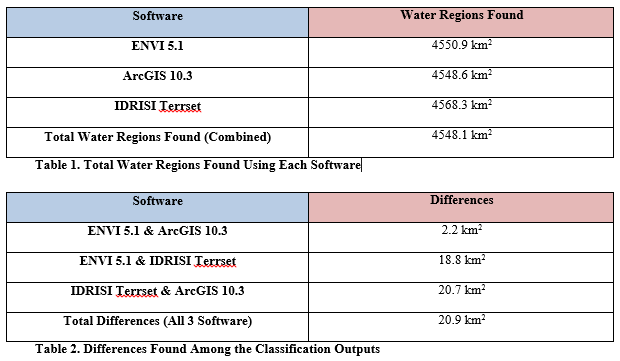
It is customary for spatial analysts to assume the implementation of various GIS software algorithms would produce the same results. If this was the case, then any errors or inaccuracies would only be a function of the input data sets and user errors. During one of my remote sensing lectures from a previous semester, my professor mentioned that we use multiple processing software in our analytical work, with each being capable of performing the same types of analyses. The topic of discussion then was on supervised classifications. This sparked my interest and thinking into how these various software execute certain supervised classification algorithms. I decided to compare three different popular software that are capable of performing supervised classifications. Using ENVI 5.1, IDRISI Terrset, and ArcGIS 10.3, I performed a maximum likelihood supervised classification on a preprocessed satellite image of the Dead Sea. My goal was to find out how much water was in the area of the image (in square kilometers). Each of the supervised classifications made use of the same training areas and the same settings (when applicable). I then compared all the results using Terrset. To my surprise, I found that all the software had produced results that varied from each other (see Tables 1 & 2).

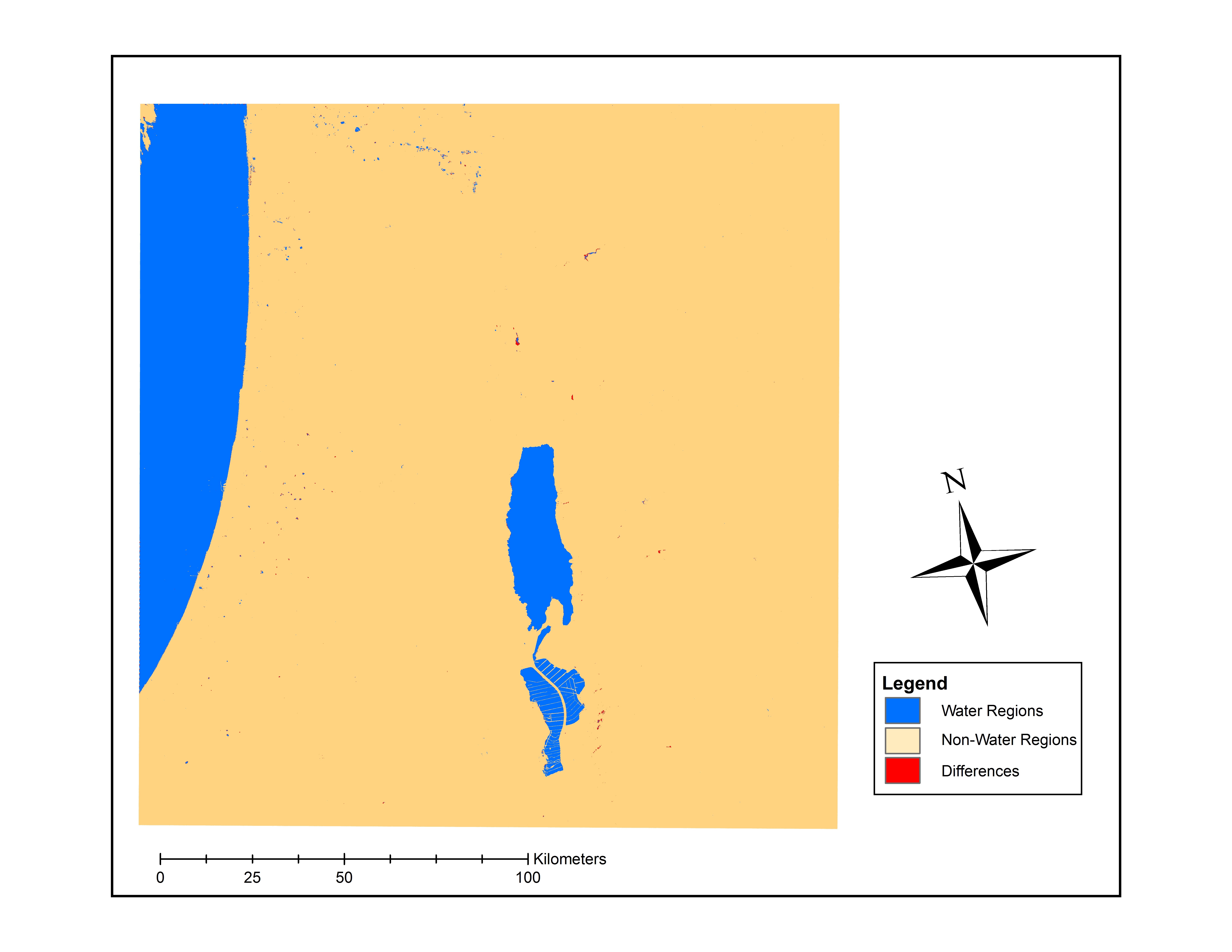
It was comforting to know that the variations in the results were relatively minor, however, they were still different from each other. In another context such as land use change or taxation these small differences will matter. I controlled for all variations in the input and parametrization of the analysis so the software implementation is the only point of departure. I am unable to comment on which software is the most accurate since I had no way of validating what the true condition was on the ground at that point in time. However, I did notice that many of the differences were found along coastlines where the depth of the water was shallower (see map below). The key takeaway for me and something I wanted to share is that our GIS outputs should be considered as a range rather than one specific value.